3.A: Do with rbioapi: Enrichment (Over-Representation) Analysis in R
Moosa Rezwani
2026-01-26
Source:vignettes/rbioapi_do_enrich.Rmd
rbioapi_do_enrich.RmdAmong the databases and web services currently supported by rbioapi Enrichr, miEAA, PANTHER, Reactome, and STRING offer Enrichment (Over-Representation) analysis API endpoints. In this article, after a brief introduction, we will demonstrate how to perform Enrichment (Over-Representation) analysis in R, consistently and easily, using the package rbioapi.
Before continuing, note that rbioapi is an interface to the databases and web services. Hence it is the user’s responsibility to cite the services they have used. We provide suggested citations in each function’s manual. However, it is the user’s responsibility to fully and adequately cite the databases or web services used in their published research.
How to install?
You can install the stable release version of rbioapi from CRAN with:
install.packages("rbioapi")However, the CRAN version is released at longer intervals, You can install the most recent -development- version from GitHub with:
install.packages("remotes")
remotes::install_github("moosa-r/rbioapi")Now, we can load the package:
What is Over-representation analysis?
Enrichment (Over-Representation) analysis is commonly performed when one’s analysis yields a list of genes, proteins, or other entities. We will not delve into details here and refer you to D. W. Huang et al.: Nucleic Acids Res. 37, 1 (2009) for a thorough review of the subject.
In short, to perform such analysis, in addition to some algorithms, two data are required:
A gene list which is derived from your analysis.
Gene sets, where genes are grouped based on a shared property or concept (such as pathway, role in diseases, physical location, etc.).
With over-representation analysis, you can compare your gene list to find if the member of any gene set are over-represented, meaning that they are present in your list in a manner that can not be explained by chance alone.
Setting up the data
Many web services supported by rbioapi provide tools to perform over-representation analysis against the gene sets curated in their databases. Among the databases and web services currently supported by rbioapi, Enrichr, miEAA, PANTHER, Reactome, and STRING provide such services. Each service has a dedicated vignette article in rbioapi. Here we will focus on performing Enrichment (Over-Representation) analysis.
As a demonstration, we will use the results of Galani et al.: Nat. Immunol. 22, 32 (2021) where they have compared the gene expression of critically ill and non-critically ill COVID patients to healthy individuals. We assign a variable with 1214 differentially expressed genes (DEGs) exclusively induced in critically ill COVID patients. Next, we will see what insights we can extract from this list.
covid_critical <- c("TXNDC5", "GABRR2", "MGAM2", "LOC200772", "LYPD2", "IFI27", "RPH3A", "OTOF", "NBPF8", "CLEC4F", "CNGB1", "HIST1H2BF", "HIF1A", "SDC1", "TUBB8", "FBXO39", "TPSB2", "CD177", "LRRN3", "EBLN2", "PCSK9", "ELK2AP", "UCHL1", "C22orf15", "LPO", "C3orf20", "CLRN1-AS1", "GPR75", "CA12", "RAB19", "CHRFAM7A", "CRYGN", "DLGAP5", "BTBD8", "LOC100272216", "PRG3", "CYP46A1", "LOC102723604", "PPAP2B", "C4BPA", "SPESP1", "LILRP2", "UBE2Q1-AS1", "MIR3945", "NOMO3", "MEG3", "LOC400927-CSNK1E", "MIR6732", "MIR590", "PPP1R3G", "PYCR1", "ARHGAP42", "MMP8", "HMMR", "P3H2", "ACER1", "NOG", "RAB39A", "ANTXRLP1", "LINC00266-3", "GPRC5D", "MCM10", "TSPY26P", "ANKRD36BP1", "GBP1P1", "PRL", "CYP1A1", "KIF4A", "LOC102724323", "SERPINB10", "GSTA4", "TRIM51", "MIXL1", "RNASE1", "CASC8", "MAOA", "XCL1", "ADAMTS2", "LOC101929125", "DCANP1", "BHLHA15", "ANOS1", "SLC18A1", "CCDC150", "CAV1", "SH3BP5", "LINC00398", "NCOA2", "SPATC1", "SHROOM2", "GPR27", "LRRC26", "RNF169", "USP3-AS1", "VWA7", "ROCK2", "FSTL4", "METTL7B", "CYP4F29P", "LEF1-AS1", "HORMAD2-AS1", "FBXO15", "PPTC7", "TYMS", "PPP4R2", "ZNF608", "FAM46B", "PCSK1N", "LINC00623", "CASC5", "ZNF224", "DENND2C", "WDR86", "PTGR1", "SPATA3-AS1", "LOC101927412", "KIF14", "MMP28", "PBK", "VMO1", "ADCY3", "HIST1H2BO", "FTO-IT1", "MIR342", "FANK1", "CRIP2", "TIAF1", "LOC344887", "OLFM4", "MKNK1-AS1", "ZDHHC19", "SEPT14", "EPSTI1", "FOXC1", "MIR616", "KRT72", "LINC01347", "LOC101928100", "KIAA0895", "BOK", "HIST1H2AI", "DBH-AS1", "ADORA2A-AS1", "MED12L", "SAMD15", "TARM1", "SMTNL1", "POU5F1P3", "LINC00968", "OAS3", "LOC103091866", "SH3RF3-AS1", "NBPF10", "APAF1", "SLC2A14", "SYT17", "ETV3", "SHROOM4", "AOAH-IT1", "NAIP", "ALAS2", "GLIS3", "ADAM17", "OLFM1", "PCAT29", "TNFRSF18", "DNASE1L3", "IGF2BP3", "LINC01271", "AP3B2", "TXNDC2", "CEP55", "SIGLEC1", "RAB3IL1", "PLD4", "KIFC1", "LINC00487", "ABHD12B", "ITGA7", "GJB6", "CARD14", "LRRN2", "MPO", "KLRC3", "LOC100507487", "SCGB3A1", "CD38", "LRRN1", "SYCP2L", "ANLN", "ASPM", "OAS1", "IFI44L", "CDCA3", "HLA-DQB2", "ANO9", "NUDT11", "HMP19", "DEPDC1", "GPR84", "PLEKHF1", "PI16", "RDH5", "TMED8", "LINC00824", "SEPT4", "CLIC3", "B4GALNT3", "OLAH", "ITGA1", "FOXI1", "LOC100506142", "CDC20", "HAGHL", "GTSCR1", "B3GALNT1", "SOCS3", "PCDH1", "TAS2R20", "CDC25A", "NPDC1", "LOC100505915", "XCL2", "TIAM2", "LOC100288069", "IL34", "IL18R1", "CYYR1", "ZNF888", "FAM20A", "MDS2", "ABCA13", "KCNJ1", "SLC4A9", "EXO1", "LAIR2", "IQSEC3", "SCT", "SLC26A8", "ESCO2", "ZDHHC1", "SNORA63", "FBLN5", "PRUNE2", "CPNE7", "CDHR2", "GNLY", "APOBEC3B", "MFSD9", "SYNGR3", "PTGDS", "COL17A1", "TBC1D14", "AIM2", "TMEM204", "FAM157B", "ZBED6", "EME1", "ATF3", "KBTBD4", "LUC7L2", "KIF20A", "LCNL1", "DOCK9-AS2", "KCNE1", "BTN2A3P", "KL", "IDI2-AS1", "EBF4", "SCARNA21", "CEACAM6", "KLRB1", "C5orf58", "ASXL2", "RPLP0P2", "CYTL1", "DIAPH3", "DOK7", "RFFL", "KIAA1107", "TAS2R40", "CCDC186", "COL6A2", "METRN", "SNHG25", "RRM2", "CYP1B1", "NEURL1", "MATK", "SLC28A3", "JCHAIN", "TNFRSF4", "FXYD1", "PLLP", "ARHGAP23", "SNORA4", "MYO18A", "ZNF429", "NRN1", "HJURP", "TCN1", "CDC6", "ATP5EP2", "SOAT2", "LOC101928034", "EIF2AK2", "ARG1", "SLC16A11", "TPPP3", "TMEM38A", "TOP2A", "LINC00999", "DGCR9", "RCAN3AS", "CACNG6", "LINC01550", "TDRD9", "CARD17", "GBP6", "LY6E", "RSAD2", "LOC100506258", "PRKAR2A", "LTF", "IGLL5", "FAM157A", "LOC101927018", "CCR7", "FLJ42351", "IFIT3", "GPRIN1", "ANXA9", "TMEM119", "PARGP1", "A3GALT2", "CYP4F22", "PLBD1-AS1", "SELM", "NCR3", "PNPLA1", "BMX", "LOC440461", "GAMT", "CEACAM8", "TP53I13", "C1orf226", "SKA3", "DHRS3", "VRK2", "BTBD19", "ETNK2", "LOC728323", "NRIR", "ADORA2A", "GPR162", "CMPK2", "USP18", "P4HA2", "TSSK4", "EP300", "CLEC4D", "LCN10", "GPR141", "SH2D2A", "GOLGA7B", "TMIGD2", "DLL4", "HP", "CXCR6", "MAL", "C12orf57", "CLIC5", "IL4", "IGFBP6", "ERG", "HERC3", "KEL", "MSX2P1", "INE1", "PRKCQ-AS1", "FHIT", "SLC1A7", "KIAA1958", "SARDH", "PFKFB3", "SNORD89", "IFI44", "DDX60", "TMEM238", "HAR1A", "EGR1", "VNN1", "TRIM9", "TAF13", "AP3S2", "TMEM56", "KLRC2", "CACNA1C-AS2", "ALX3", "FCGBP", "CD247", "ALDH1L2", "HIST1H2AC", "RTP5", "PPARG", "AMPH", "LINC00861", "CDKL5", "MYBL2", "LOC101927051", "TLR5", "TMEM121", "BMP8B", "AK5", "RBP5", "LINC01355", "PITRM1-AS1", "CMTM1", "BIRC5", "C10orf10", "TNFRSF25", "ZAP70", "LOC105373383", "DSP", "WDR86-AS1", "RPLP2", "KREMEN1", "LOC101927550", "PDZD4", "LOC100130451", "MKI67", "LOC728743", "CXCL10", "LINC01547", "LOC645513", "ATOH8", "S1PR5", "KISS1R", "MELK", "TCEA3", "SLC22A20", "RAMP1", "FOLR2", "GGT6", "CACNA1E", "FABP6", "RAP2C-AS1", "PRRG4", "FAM63B", "BLK", "P3H3", "WIPF2", "TROAP", "FAHD2CP", "CA6", "LINC00892", "LRCH3", "BUB1B", "LOC100996286", "NT5E", "PASK", "BATF2", "TTC39C-AS1", "ACTA2", "CHIT1", "LAMC1", "TNFAIP3", "ANKRD22", "C12orf42", "SPON2", "SLX4IP", "TNNC1", "ZNF771", "SPEG", "HIST1H4H", "HTR6", "TNFRSF17", "FSD1", "LINC00266-1", "CD6", "PRSS30P", "SFTPD", "COPZ2", "BPI", "CCIN", "CDK1", "ATP2C2", "GOLGA8H", "USP44", "SLC14A1", "ZDHHC14", "SNORD50A", "LTK", "KCNG2", "MAPK11", "ACOT4", "CTSW", "C1orf106", "CDKN3", "UPB1", "CAMK2N1", "RBM5-AS1", "DNLZ", "GZMM", "PLA2G7", "ZCCHC2", "PRSS41", "RPL13", "OLR1", "BCAS4", "EPB41", "TRABD2A", "PBX4", "GZMK", "PNPLA7", "B4GALT5", "ARHGEF17", "APOA1", "GPA33", "KLRG1", "GBP5", "LOC102723701", "CENPA", "LOC285696", "KCNK5", "SUSD4", "RPS28", "ESPL1", "ITGB4", "SPAG16", "CYP4F35P", "CD3D", "BMS1P20", "CBS", "ETV2", "SPATS2L", "DUSP13", "FAM19A1", "VSIG10L", "CD2", "NHSL2", "FAAH2", "FXYD7", "NTN5", "FICD", "GLDC", "LOC101927865", "LINC00944", "PTPRCAP", "GNB3", "TRIM22", "PRRT1", "NR1I3", "BTN3A1", "STX16-NPEPL1", "TMEM191A", "SERPINB2", "UST", "GALNT12", "BUB1", "GTF2I", "FOSL2", "COL13A1", "RGS9", "NCALD", "DNAH10", "CA11", "CKB", "HSPB1", "CDC45", "ATP7B", "WNT5B", "ZNF699", "PRRT4", "GALNT14", "ZNF319", "DNAH17", "LOC283710", "CPEB4", "LY6G6C", "PPAN", "WASH5P", "HIST1H3H", "IL32", "TEPP", "CNR1", "YJEFN3", "FAM159A", "FGFBP2", "FKBP5", "BIN1", "VPREB3", "E2F8", "HK3", "CDH2", "HFE", "BEAN1-AS1", "KIFC3", "HELB", "HLA-DPB1", "GZMH", "LMNB1", "CC2D2A", "IQCH-AS1", "CTSF", "TMEM132D", "LEF1", "REL", "CBR3", "WNT10B", "LOC100289473", "APBA2", "KIF23", "LOC646471", "PNMA6A", "EPC2", "HBEGF", "S100B", "C14orf132", "KCND1", "SIPA1L2", "NCAPG", "OAS2", "C3AR1", "CSF1", "CHCHD6", "AUTS2", "IL24", "CDC42EP2", "LTBP3", "PXT1", "ADAMTS10", "BLZF1", "TPST1", "ID3", "GYG1", "EFCAB2", "MYO10", "TLE2", "SLC30A1", "CCNI", "WNT7A", "RBL2", "ERICH6-AS1", "IGFBP3", "DTL", "SORBS3", "RPS19", "SMA4", "RPS27", "BEAN1", "MIRLET7BHG", "ABCA1", "ZKSCAN7", "GPR34", "GPR153", "TRIM52", "GRASP", "RNASE2", "CENPF", "ACTG1P20", "MMP9", "ZFP82", "RTN1", "RPS21", "PCBP1-AS1", "PVRL3", "RPS10", "FER1L4", "SEPT1", "DEPDC1B", "LINC00926", "SEC14L2", "LOC100420587", "PCSK4", "HPS3", "KIR3DL1", "SPRN", "HRH2", "FAHD2B", "P3H4", "TMEM160", "ENGASE", "RAD51AP1", "ZNF233", "RAP1GAP", "TTBK2", "PINK1", "SH2D1B", "BAIAP2L1", "BECN1", "RPL13A", "INHBB", "HPCAL4", "TPM2", "ACVR2B", "CEP126", "RPL18", "B3GNT7", "ROBO3", "MYOM2", "SLC51A", "CCL5", "PROSER3", "RPL18A", "SERINC4", "ATP11B", "SMARCD3", "STMN3", "FAM173A", "CDK5RAP2", "GGH", "EIF4G3", "C18orf32", "SHCBP1", "CCM2L", "LAT", "PRF1", "ARL15", "WHAMMP1", "NBN", "ARHGEF11", "ZWINT", "BTBD11", "MCOLN2", "EYS", "GRAP", "TAP1", "FAM157C", "ANXA3", "MCEMP1", "TCF7", "IGSF9B", "SDSL", "LNPEP", "NSUN5P1", "FAM110B", "SPNS3", "ACTL10", "GCSAM", "LOC101927482", "UGCG", "CD24", "SCO2", "GMCL1", "SAMD12", "NUSAP1", "WNT1", "NME3", "LOC728084", "RGS18", "PNMA3", "KLRF1", "ENO2", "SUPT3H", "ATP5D", "ZC3H13", "PSTPIP2", "SNORD81", "SESN2", "TK1", "LHFPL2", "SCARNA10", "SERPING1", "SYT2", "SNORA33", "JAK2", "CYB5D1", "SH3RF3", "ARL14EP", "UBASH3A", "ARL5B", "SPRED2", "NELL2", "PPP2R2B", "CDH12", "WDR54", "KLF4", "MTUS1", "ELF1", "CARNS1", "CLEC10A", "CD3E", "TTK", "KBTBD7", "TPX2", "ZNF69", "AICDA", "TAMM41", "LOC100288152", "AK1", "MMP24", "SAMD9L", "RAD51", "ACE", "COLGALT2", "NEDD4", "SPEF2", "CENPE", "CRISPLD2", "TSEN54", "RCVRN", "FRMD3", "SKAP1", "CYP4F3", "TMEM161B-AS1", "KANSL1L", "SLC29A2", "CEP97", "XAF1", "CDKN1C", "PRDM5", "HBP1", "CACNG8", "RP2", "OASL", "NPIPA1", "ZNF354A", "RPL32", "GLTSCR2", "CD52", "SBK1", "ZNF703", "GBP1", "C4orf29", "ERV3-1", "ABCC2", "EPB41L5", "FFAR3", "PLEKHB1", "LOC100507387", "RPL36", "PRC1", "C19orf60", "PRSS23", "CD160", "HOPX", "SAMD10", "RPSAP9", "CDCA2", "SWT1", "NPEPL1", "RORC", "MS4A3", "BCL2L15", "CXCR5", "EPHX2", "B3GNT9", "CDCA7L", "LMTK2", "UBAP1L", "CD79B", "OBSCN", "TMEM102", "ZNF540", "SPP1", "HABP4", "LOC100130872", "APBB1", "GPC2", "CD1C", "LONRF3", "NR2C2", "NSUN7", "SIGIRR", "SNORD38B", "FAM65C", "HELZ2", "ARL4D", "ENO3", "RPL9", "IFT81", "LSMEM2", "SCARNA2", "CD5", "AHNAK2", "RPL27A", "SOX8", "TMEM161A", "ZNF81", "PXK", "LOC441081", "RPS26", "CCNB1", "PLXDC1", "NFKBIA", "PKMYT1", "SLC27A5", "LRRC4", "TARP", "MAP2K6", "EIF1B-AS1", "SCARNA17", "NUDT8", "EAF1", "TBC1D8", "SESTD1", "CLEC12B", "ZNF776", "PDCD1", "FBXL16", "SLFN14", "ATP8B3", "ZNF396", "STOM", "CCDC30", "FAM86FP", "FAM129C", "TMEM42", "ZNF607", "IL11RA", "ECHDC2", "CCNE2", "PUS7L", "EFCAB12", "TGFA", "MAPK14", "NSG1", "C9orf142", "KLHL15", "LOC102723766", "VEGFB", "TJP3", "YAE1D1", "PROS1", "CSGALNACT2", "HLA-DOA", "TUBBP5", "RPL37A", "FAM195A", "LTB4R2", "NCAPH", "EVL", "CR1", "LTC4S", "ANKS3", "RPL35", "GLIS2", "TRAPPC6A", "LIPN", "RPS12", "RPL38", "LIME1", "PHGDH", "C4orf48", "SLED1", "BACH2", "EVA1C", "GATA3", "SLC25A38", "USP32", "RPL39", "EGR2", "USP35", "ZNF662", "PLEKHG1", "CRTAM", "AANAT", "OPLAH", "FBXO6", "LOXL1", "LOC101928786", "FRMD4B", "IL1R1", "ADM2", "DNASE1L1", "STAT4", "RPLP1", "TTC9", "BEND7", "F8", "FOSB", "SLAMF6", "STK17B", "PVT1", "ARVCF", "APOBEC3C", "CDK14", "RPS14", "POLQ", "CDC42BPG", "CCDC85B", "UBR5-AS1", "TNNT3", "TCL1A", "IL7R", "PTX3", "KLHL14", "MTRNR2L1", "ZBTB46", "RPL34", "VPS9D1-AS1", "KLF7", "RPL10A", "SLC2A11", "ACTN4", "RPSA", "SGK223", "PLSCR1", "SBF2", "LINC01420", "CDCA5", "F5", "ADGRB2", "RPL23A", "MAN1A2", "LLGL2", "GINS2", "NUDT14", "TG", "RSRC1", "TMEM256", "SYTL2", "TYSND1", "TPGS1", "ABHD14B", "LSM7", "ZNF281", "CEMP1", "M1AP", "CD82", "LOC101928150", "MRPL41", "IFIH1", "CCNB2", "IFITM10", "RPS3A", "TMEM8B", "CEP135", "SIRPB2", "IRS2", "SYCE1L", "SULT1B1", "ADAM9", "ZCCHC18", "DDIAS", "LINC01278", "MTHFD2", "TIGIT", "FUOM", "FOSL1", "RPS16", "BRAF", "CACNA1I", "EXT1", "GPR82", "LRRC45", "STAG1", "KIF11", "NCAM1", "RNF24", "KIAA2018", "SAMD9", "ABCA2", "PVRIG", "RASGRF2", "IRAK2", "ARHGEF4", "ZNF682", "RASSF7", "THAP7", "KIF1B", "GAS5", "KIF15", "RMRP", "GALM", "LYNX1", "C7orf50", "ATXN1L", "KCNN4", "LDLRAP1", "RETSAT", "RNF10", "NOXA1", "UBXN7", "UHRF1BP1L", "TESPA1", "MB21D1", "LINC00116", "FOXM1", "CCR6", "NMUR1", "RPL22", "LCK", "MEGF9", "CLSPN", "MIR4697HG", "PPP1R15A", "ADCK5", "SAMD3", "RPS27A", "TPPP", "PIWIL4", "ANKRD33B", "IL18RAP", "SNRPD2", "WASF1", "ALDH5A1", "FAM149B1", "RPS18", "SLCO4C1", "MGC16275", "ZNF837", "SAMHD1", "NSMF", "PDIA6", "SNX20", "ATF7IP2", "BPHL", "RPL35A", "NFKBIZ", "LMF1", "MGMT", "PPL", "FAM120C", "APRT", "RANGRF", "PHLDB3", "IDNK", "RPS15", "LGR6", "MOB1A", "CREB5", "THEM4", "ENDOG", "RPL7", "EDN1", "ZNF808", "SNHG15", "RPL3", "SMCR8", "FCMR", "ZNF449", "ZBTB37", "NHLRC4", "DHRS9", "C1QTNF3", "MS4A1", "AFF2", "FBXO32", "SLC6A6", "ZSCAN30", "CHPT1", "PARP14", "MZT2B", "FLT3LG", "TCTN2", "MAN1A1", "LOC728175", "ALOX5", "DUSP18", "ZC3H12D", "PECR", "LRRC37A3", "EPB41L4A-AS1", "SPAG5", "KDM7A", "DDX31", "NCOA6", "SLC6A12", "FCER1A", "FBXL13", "AKR7A2", "PRR5", "PRKCE", "PPP1R3D", "SYNM", "GLI1", "NTNG2", "EEF1G", "LOC643802", "MAGEE1", "PIK3AP1", "RPS8", "SNHG19", "C19orf70", "GAS7", "PHF12", "ATP11A", "SLC22A23", "ATP6V0E2", "UCKL1-AS1", "TIPARP", "BEX2", "FAM102A", "RPS20", "TTC16", "PLP2", "HAPLN3", "C19orf24", "ZNF397", "FOXO4", "TRAPPC2B", "QTRT1", "CDK10", "PDZD8", "GIPC1", "CD274", "C9orf139", "SPIB", "KLHDC7B", "ZNF32", "ELMO2", "AK4", "SAMD4B", "MFSD3", "EXD3", "SLC37A3", "RPL8", "TRIM56", "NMB", "PIPOX", "PXN-AS1", "SLC2A5")Please Note: Over-representation services return large responses. To reduce the size of this vignette article, we will only display the first 10 rows of each Data Frame.
Enrichr
Enrichr , developed in the Ma’ayan Lab, is a service to perform enrichment analysis against a considerable number of curated gene set libraries across various species.
We have thoroughly covered performing enrichment analysis with Enrichr in the vignette article Enrichr & rbioapi. Therefore, we will only provide a brief demonstration here.
First, let us retrieve a list of available libraries in Enrichr using
the rba_enrichr_libs() function. You can find the available
Enrichr libraries in the libraryName column in the returned
data frame.
enrichr_libs <- rba_enrichr_libs(organism = "human")
#> Retrieving List of available libraries and statistics from Enrichr human.While the only required argument of rba_enrichr()
function is gene_list, here we use
gene_set_library argument to request an enrichment analysis
only against “KEGG_2021_Human” library.
enrichr_enrich <- rba_enrichr(
gene_list = covid_critical,
organism = "human",
gene_set_library = "KEGG_2021_Human",
progress_bar = FALSE # to avoid printing issues in the vignette
)
#> --Step 1/3:
#> Retrieving List of available libraries and statistics from Enrichr human.
#> --Step 2/3:
#> Uploading 1214 gene symbols to Enrichr human.
#> --Step 3/3:
#> Performing Enrichr analysis on gene-list 116121333 against Enrichr human library: KEGG_2021_Human.In the gene_set_library parameter, you can also provide
multiple gene set libraries or leave it as the default parameter
NULL to perform the enrichment analysis using every gene
set library available in Enrichr. Also note that when
regex_library_name parameter is TRUE (the default value),
gene_set_library parameter will be considered as a regex
pattern, so partial matchs will be also selected.
enrichr_enrich_kegg <- rba_enrichr(
gene_list = covid_critical,
gene_set_library = "kegg",
regex_library_name = TRUE, # default value
progress_bar = FALSE # to avoid printing issues in the vignette
)
#> --Step 1/3:
#> Retrieving List of available libraries and statistics from Enrichr human.
#> --Step 2/3:
#> Uploading 1214 gene symbols to Enrichr human.
#> --Step 3/3:
#> Performing Enrichr analysis on gene-list 116121340 using multiple Enrichr human libraries.
#> Note: You have selected '7' Enrichr human libraries. Note that for each library, a separate call should be sent to Enrichr server. Thus, this could take a while depending on the number of selected libraries.As you can see below, when than one library is selected, the results will be a list where each of its elements is the enrichment results of one library:
str(enrichr_enrich_kegg, max.level = 1)
#> List of 7
#> $ KEGG_2013 :'data.frame': 139 obs. of 9 variables:
#> $ KEGG_2015 :'data.frame': 131 obs. of 9 variables:
#> $ KEGG_2016 :'data.frame': 260 obs. of 9 variables:
#> $ KEGG_2019_Human:'data.frame': 272 obs. of 9 variables:
#> $ KEGG_2019_Mouse:'data.frame': 267 obs. of 9 variables:
#> $ KEGG_2021_Human:'data.frame': 285 obs. of 9 variables:
#> $ KEGG_2026 :'data.frame': 312 obs. of 9 variables:It is also possible to provide a background gene list for Enrichr analysis. This feature is only supported when the organism is set to “human”.
Reactome Analysis services
Reactome curates extensive and top-quality cellular pathways data across various species. Given the fact that proteins operate in organized units, which are the pathways, analyzing your list against Reactome pathways gene sets can provide valuable insights into the functional trajectories of your results.
You can refer to Reactome & rbioapi article for in-depth coverage of Reactome services. Here we will only demonstrate the over-representation functionality
The function rba_reactome_analysis() accepts gene lists
or a table as input. If a table is supplied, the first column should
consist of identifiers, and the next column should be numerical gene
expression values. Refer to rba_reactome_analysis()
function’s manual for details. Here, we will use our gene list of
critical COVID:
reactome <- rba_reactome_analysis(input = covid_critical)
#> Retrieving Reactome Analysis Results of your supplied Identifiers.Let us examine the response’s structure:
str(reactome, max.level = 1)
#> List of 8
#> $ summary :List of 7
#> $ expression :List of 1
#> $ identifiersNotFound: int 557
#> $ pathwaysFound : int 1615
#> $ pathways :'data.frame': 1615 obs. of 19 variables:
#> $ resourceSummary :'data.frame': 4 obs. of 3 variables:
#> $ speciesSummary :'data.frame': 1 obs. of 5 variables:
#> $ warnings : list()The list’s element names are self-explanatory. The results are
returned as a data frame in the pathways element. Note that
Reactome will map your provided gene identifiers and some identifiers
may not be found. Hence, keep an eye on the
identifiersNotFound element.
Naturally, you can alter the analysis parameters using the
rba_reactome_analysis() function’s arguments. The used
parameters are returned in the “summary” element.
str(reactome$summary)
#> List of 7
#> $ token : chr "MjAyNjAxMjMwNjE2NTdfMTQ3"
#> $ projection : logi TRUE
#> $ interactors : logi FALSE
#> $ type : chr "OVERREPRESENTATION"
#> $ sampleName : chr "Gene names"
#> $ text : logi TRUE
#> $ includeDisease: logi TRUEIn the above code chunk, note the “token” associated with your analysis. You can use this token to perform the following.
Retrieve the analysis results:
reactome_2 <- rba_reactome_analysis_token(reactome$summary$token)In addition to the main response, you can download other data
associated with your request. see the argument request in
the rba_reactome_analysis_download() function’s manual for
more information. Here, we will download a CSV file with the input
identifiers which has not been found:
rba_reactome_analysis_download(
token = reactome$summary$token,
request = "not_found_ids",
save_to = "my_analysis.csv"
)Reactome also generates a nice report of your analysis in pdf format, make sure to try it:
rba_reactome_analysis_pdf(
token = reactome$summary$token,
species = 9606, #Homo sapiens
save_to = "my_analysis.pdf"
)PANTHER
PANTHER (protein analysis through evolutionary relationships) is a project that provides classification systems of genes and proteins. PANTHER also provides an enrichment service. In fact, the enrichment tool available on the Gene Ontology (GO) website is powered by PANTHER. Just like the previous sections, we will only review the enrichment functionality here; for an in-depth review of PANTHER refer to the vignette article “PANTHER & rbioapi”.
To perform the analysis, first, we need to choose the annotation datasets (i.e. a collection of gene sets) that we want to compare our results against it. To retrieve a list of available annotation datasets, we call the following function:
panther_sets <- rba_panther_info(what = "datasets")
#> Retrieving available annotation datasets.Note that you should enter the “id” of the datasets, not its label.
For example, entering "biological_process" is incorrect,
you should rather use "GO:0008150".
Here, we demonstrate the enrichment analysis using the Biological Process annotations. The Gene Ontology (GO) project is one of the pinnacles of scientists’ collective effort in bioinformatics. The GO Consortium provides a comprehensive model of biological systems. In short, GO curates a thoroughly designed directed acyclic graph (DAG) of ontologies. You may think of it as a tree of terms, where as it branches out, the terms become more specific). Each protein may be annotated with one or more terms. The terms are organized in three domains: “Molecular Function,” “Biological Process,” and “Cellular Component”. GO slim datasets refer to subsets which are a cut-down version of GO terms. If you are not familiar with GO, I strongly encourage you to see this page and follow the links it provides: About the GO resource.
Depending on the provided input, PANTHER will conduct two types of analysis:
If a character vector is supplied, over-representation analysis will be performed using either Fisher’s exact or binomial test.
If a data frame with gene identifiers and their corresponding expression values is supplied, statistical enrichment test is performed using Mann-Whitney U (Wilcoxon Rank-Sum) test.
rbioapi determines the proper analysis based on the class of the
genes parameter. Please refer to the details section of
rba_panther_enrich() function manual and rbioapi &
PANTHER vignette article for more information.
Here, we only demonstrate using a gene list, without the expression values:
panther_enrich <- rba_panther_enrich(
genes = covid_critical,
organism = 9606, #Homo sapiens
annot_dataset = "GO:0008150" #Biological Process
)
#> Performing PANTHER over-representation analysis (Fisher's exact test) on 1214 genes from `organism 9606` against `GO:0008150` datasets.In addition to the results table, PANTHER returns other useful information about your analysis. The names are self-explanatory:
str(panther_enrich, 2)
#> List of 9
#> $ reference :List of 3
#> ..$ organism : chr "Homo sapiens"
#> ..$ mapped_count :List of 2
#> ..$ unmapped_count: int 0
#> $ input_list :List of 5
#> ..$ organism : chr "Homo sapiens"
#> ..$ mapped_ids : chr "SCT,C4BPA,FAM159A,TSEN54,VPREB3,ZC3H12D,SPIB,HTR6,SAMD15,PPP4R2,FAM110B,LIPN,C3AR1,EPSTI1,UBASH3A,SAMD12,SAMD10"| __truncated__
#> ..$ mapped_count : int 1040
#> ..$ unmapped_ids : chr "LOC200772,ELK2AP,CLRN1-AS1,LOC100272216,LOC102723604,LILRP2,UBE2Q1-AS1,MIR3945,MEG3,LOC400927-CSNK1E,MIR6732,MI"| __truncated__
#> ..$ unmapped_count: int 174
#> $ result :'data.frame': 14535 obs. of 9 variables:
#> ..$ number_in_list : int [1:14535] 38 21 21 23 24 107 199 104 145 137 ...
#> ..$ fold_enrichment : num [1:14535] 5.4 8.46 8.29 6.95 6.45 ...
#> ..$ fdr : num [1:14535] 5.57e-14 3.39e-11 3.76e-11 1.42e-10 2.20e-10 ...
#> ..$ expected : num [1:14535] 7.03 2.48 2.53 3.31 3.72 ...
#> ..$ number_in_reference: int [1:14535] 136 48 49 64 72 1049 2457 1037 1667 1542 ...
#> ..$ pValue : num [1:14535] 3.83e-18 4.66e-15 7.76e-15 3.92e-14 7.58e-14 ...
#> ..$ plus_minus : chr [1:14535] "+" "+" "+" "+" ...
#> ..$ term.id : chr [1:14535] "GO:0002181" "GO:1901740" "GO:0034242" "GO:1901739" ...
#> ..$ term.label : chr [1:14535] "cytoplasmic translation" "negative regulation of myoblast fusion" "negative regulation of syncytium formation by plasma membrane fusion" "regulation of myoblast fusion" ...
#> $ search :List of 1
#> ..$ search_type: chr "overrepresentation"
#> $ tool_release_date : int 20240807
#> $ enrichment_test_type : chr "FISHER"
#> $ annotDataSet : chr "GO:0008150"
#> $ annot_version_release_date: chr "GO Ontology database DOI: 10.XXXX/zenodo.XXXXXXXX Released 2025-10-05"
#> $ correction : chr "FDR"The analysis results are returned as a Data Frame with an element named result:
STRING
In addition to proteins interaction data, STRING also curates proteins/genes annotations and provides enrichment analysis services. You can perform the analysis against multiple gene sets. Some of the gene sets can be accessed using other services but two gene sets are exclusive to STRING. See “D. Szklarczyk et al.: Nucleic Acids Res. 49, D1 (2021)” for further information. Again. We will only review the enrichment functionality here; for an in-depth review of STRING refer to the vignette article “STRING & rbioapi”.
-
Gene sets exclusively in STRING:
Reference Publications (PubMed)
-
Gene sets also available in other services:
Gene Ontology domains: Molecular Function, Biological Process, and Cellular Component
We can directly supply our covid_critical variable to
STRING’s enrichment function:
string_enrich <- rba_string_enrichment(
ids = covid_critical,
species = 9606 #Homo sapiens
)
#> Performing functional enrichment of 1214 Input Identifiers.As you can see, by default a list is returned where each element is a data Frame with enrichment analysis results against one of the gene sets listed above:
str(string_enrich, max.level = 1)
#> List of 13
#> $ COMPARTMENTS :'data.frame': 18 obs. of 10 variables:
#> $ Component :'data.frame': 19 obs. of 10 variables:
#> $ DISEASES :'data.frame': 10 obs. of 10 variables:
#> $ Function :'data.frame': 1 obs. of 10 variables:
#> $ HPO :'data.frame': 3 obs. of 10 variables:
#> $ KEGG :'data.frame': 6 obs. of 10 variables:
#> $ Keyword :'data.frame': 18 obs. of 10 variables:
#> $ NetworkNeighborAL:'data.frame': 46 obs. of 10 variables:
#> $ PMID :'data.frame': 100 obs. of 10 variables:
#> $ Process :'data.frame': 77 obs. of 10 variables:
#> $ RCTM :'data.frame': 49 obs. of 10 variables:
#> $ TISSUES :'data.frame': 14 obs. of 10 variables:
#> $ WikiPathways :'data.frame': 3 obs. of 10 variables:In the “PMID” element, we see which PubMed papers are
over-represented with our gene list. To keep the table tidy, we are not
displaying the inputGenes and preferredNames
columns.
You can retrieve the annotations associated with your input
protein(s). The difference here is that no statistical analysis will be
performed and the full annotations of your input gene will be returned.
Because of potentially unwieldy response, allow_pubmed is
set fo FALSE by default. Here we set it to TRUE to also retrieve the
PubMed paper abstracts that include our gene.
string_annot <- rba_string_annotations(
ids = "CD177",
species = 9606, #Homo sapiens
allow_pubmed = TRUE
)
#> Retrieving functional annotations of 1 Input Identifiers.As you can see, Our input gene has a large number of annotations. Let us take a look at the PMID Data Frame, which contains the PubMed Abstract paper terms:
str(string_annot, max.level = 1)
#> List of 13
#> $ COMPARTMENTS :'data.frame': 31 obs. of 8 variables:
#> $ Component :'data.frame': 43 obs. of 8 variables:
#> $ DISEASES :'data.frame': 6 obs. of 8 variables:
#> $ Function :'data.frame': 9 obs. of 8 variables:
#> $ HPO :'data.frame': 8 obs. of 8 variables:
#> $ InterPro :'data.frame': 2 obs. of 8 variables:
#> $ Keyword :'data.frame': 13 obs. of 8 variables:
#> $ NetworkNeighborAL:'data.frame': 5 obs. of 8 variables:
#> $ Pfam :'data.frame': 1 obs. of 8 variables:
#> $ PMID :'data.frame': 2486 obs. of 8 variables:
#> $ Process :'data.frame': 92 obs. of 8 variables:
#> $ RCTM :'data.frame': 7 obs. of 8 variables:
#> $ TISSUES :'data.frame': 13 obs. of 8 variables:In addition to a data frame, you can also get a plot summarizing the
enrichment results. This API endpoint supports extensive customization
of the plot; please refer to the
rba_string_enrichment_image() function’s manual for
detailed instructions. Here we perform an enrichment analysis against
the KEGG database, and retrieve a plot of the results.
enrich_plot <- rba_string_enrichment_image(
ids = covid_critical,
species = 9606,
category = "KEGG",
image_format = "image",
save_image = FALSE,
group_by_similarity = 0.6
)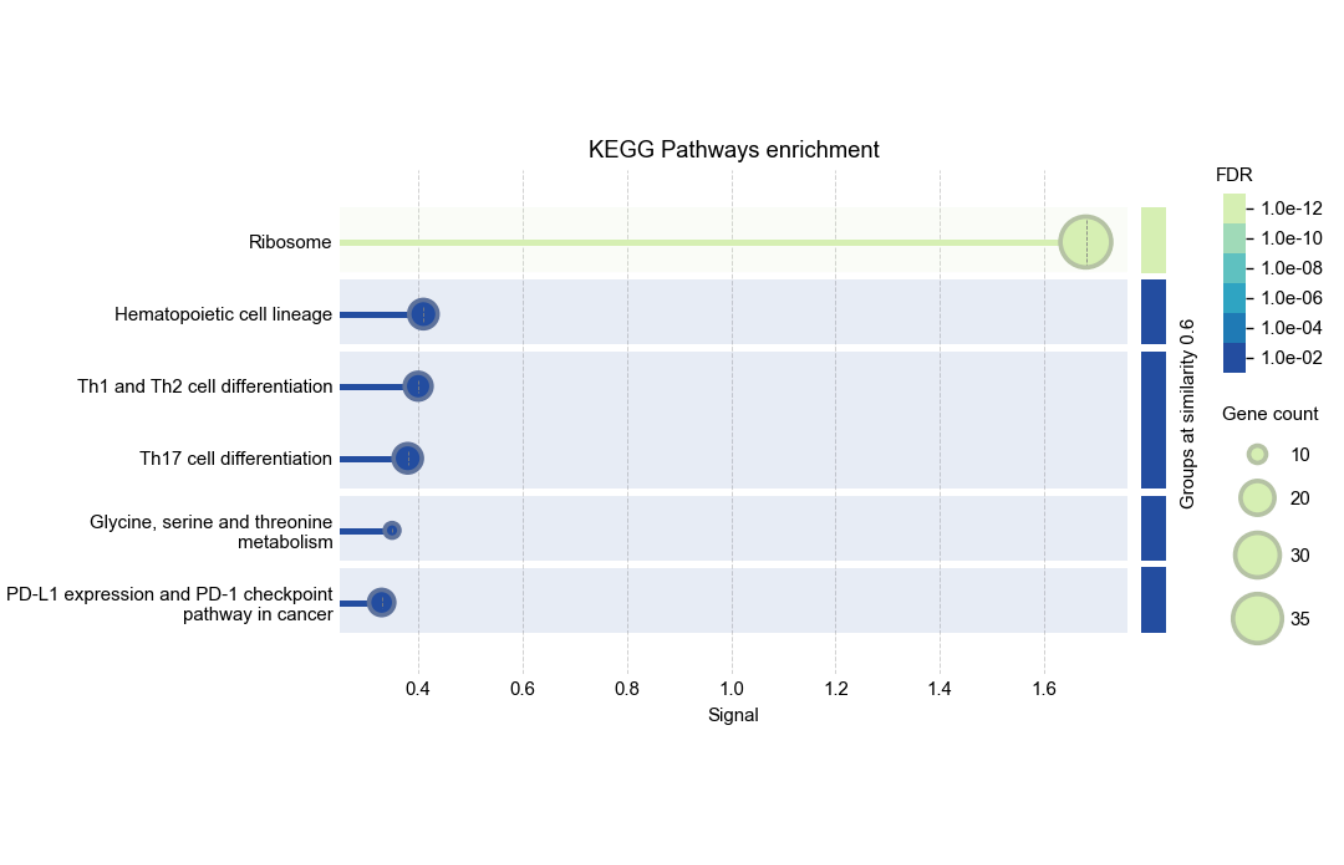
Visualization of enrichment analysis results
miEAA
The miRNA Enrichment Analysis and Annotation Tool (miEAA) is a service provided by the Chair for Clinical Bioinformatics at Saarland University. What makes miEAA unique among other services presented here is that miEAA curates miRNA sets. Hence you can directly perform miRNA enrichment analysis across various species with the services miEAA provides.
We have in-depth covered performing enrichment analysis with miEAA in the vignette article “miEEA & rbioapii”. Therefore, we will only provide a brief demonstration here.
We can not use our covid_critical gene list here. We
rather use a miRNA list from the paper “A.
Parray et al.: Vaccines 9, 1056 (2021)”. They used microarray to
find differentially expressed miRNA in the severe versus mild COVID 19
patients’ blood.
covid_mirna <- c(
"hsa-miR-3609", "hsa-miR-199a-5p", "hsa-miR-139-5p", "hsa-miR-145-5p",
"hsa-miR-3651", "hsa-miR-1273h-3p", "hsa-miR-4632-5p", "hsa-miR-6861-5p",
"hsa-miR-6802-5p", "hsa-miR-5196-5p", "hsa-miR-92b-5p", "hsa-miR-6805-5p",
"hsa-miR-98-5p", "hsa-miR-3185", "hsa-miR-572", "hsa-miR-371b-5p",
"hsa-miR-3180", "hsa-miR-8073", "hsa-miR-4750-5p", "hsa-miR-6075",
"hsa-let-7i-5p", "hsa-miR-1231", "hsa-miR-885-3p"
)While not necessary, we can first see what enrichment categories are available for our mature human miRNA:
rba_mieaa_cats(
mirna_type = "mature",
species = 9606 #Homo sapiens
)
#> Retrieving available enrichment categories of miRNA for Homo sapiens.
#> Annotations derived over miRTarBase (Gene Ontology)
#> "GO_Annotations_indirect_mature"
#> Annotation (Gene Ontology)
#> "GO_Annotations_mature"
#> Pathways (KEGG)
#> "KEGG_mature"
#> exRNA forms (miRandola)
#> "miRandola_mature"
#> Chromosomal location (miRBase)
#> "miRBase_Chromosomes_mature"
#> Conservation (miRBase)
#> "miRBase_Conserved_miRNAs_5_organisms_mature"
#> Confidence (miRBase)
#> "miRBase_High_confidence_mature"
#> Seed family (miRBase)
#> "miRBase_Seed_family_mature"
#> GO Biological process (miRPathDB)
#> "miRPathDB_GO_Biological_process_mature"
#> GO Cellular component (miRPathDB)
#> "miRPathDB_GO_Cellular_component_mature"
#> GO Molecular function (miRPathDB)
#> "miRPathDB_GO_Molecular_function_mature"
#> KEGG (miRPathDB)
#> "miRPathDB_KEGG_mature"
#> Reactome (miRPathDB)
#> "miRPathDB_Reactome_mature"
#> WikiPathways (miRPathDB)
#> "miRPathDB_WikiPathways_mature"
#> Target genes (miRTarBase)
#> "miRTarBase_mature"
#> Diseases (miRWalk)
#> "miRWalk_Diseases_mature"
#> Gene Ontology (miRWalk)
#> "miRWalk_GO_mature"
#> Organs (miRWalk)
#> "miRWalk_Organs_mature"
#> Pathways (miRWalk)
#> "miRWalk_Pathways_mature"
#> Diseases (MNDR)
#> "MNDR_mature"
#> Interactions (NPInter)
#> "NPInter_mature"
#> Gender/Age
#> "Published_Age_gender_mature"
#> Cell-type specific (Atlas)
#> "Published_cell_specific_mature"
#> Cell-type specific (Cellular microRNAome)
#> "miRNAome_mature"
#> Published Diseases
#> "Published_Diseases_mature"
#> Immune cells
#> "Published_Immune_cells_mature"
#> Localization (RNALocate)
#> "RNALocate_mature"
#> Drugs (SM2miR)
#> "SM2miR_mature"
#> Expressed in tissue (Tissue Atlas)
#> "TissueAtlas_mature"
#> Tissue specific (isomiRdb)
#> "isomiRdb_tissue_specific_mature"
#> High confidence (MirGeneDB)
#> "MirGeneDB_High_confidence_mature"
#> isomiRs (isomiRdb)
#> "isomiRdb_mature"Next, we will use the wrapper function available to perform the necessary steps in one function call. Note that we have supplied the categories parameter. If left NULL, the enrichment will be performed against every available category.
mieaa_enrich <- rba_mieaa_enrich(
test_set = covid_mirna,
mirna_type = "mature",
test_type = "ORA",
species = 9606,
categories = "miRPathDB_GO_Biological_process_mature"
)
#> -- Step 1/3: Submitting Enrichment analysis request:
#> Submitting ORA enrichment request for 23 miRNA IDs of species Homo sapiens to miEAA servers.
#>
#> -- Step 2/3: Checking for Submitted enrichment analysis's status every 5 seconds.
#> Your submitted job ID is: 4ce81b88-5e9d-4396-bec8-c4e83afcf4c5
#> .
#>
#> -- Step 3/3: Retrieving the results.
#> Retrieving results of submitted enrichment request with ID: 4ce81b88-5e9d-4396-bec8-c4e83afcf4c5How to cite?
rbioapi is an interface between you and other databases and services. Thus, if you have used rbioapi in published research, in addition to kindly citing rbioapi, ensure to fully and properly cite the databases/services you have used. Suggested citations have been added in the functions’ manuals, under the “references” section; Nevertheless, it is the user’s responsibility to check for proper citations and to properly cite the database/services that they have used.
Please see the rbioapi’s main vignette article for more details.
Session info
#> R version 4.5.2 (2025-10-31)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.3 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] rbioapi_0.8.3
#>
#> loaded via a namespace (and not attached):
#> [1] httr_1.4.7 cli_3.6.5 knitr_1.51 rlang_1.1.7
#> [5] xfun_0.56 otel_0.2.0 png_0.1-8 textshaping_1.0.4
#> [9] jsonlite_2.0.0 DT_0.34.0 htmltools_0.5.9 ragg_1.5.0
#> [13] sass_0.4.10 rmarkdown_2.30 grid_4.5.2 crosstalk_1.2.2
#> [17] evaluate_1.0.5 jquerylib_0.1.4 fastmap_1.2.0 yaml_2.3.12
#> [21] lifecycle_1.0.5 compiler_4.5.2 fs_1.6.6 htmlwidgets_1.6.4
#> [25] systemfonts_1.3.1 digest_0.6.39 R6_2.6.1 curl_7.0.0
#> [29] magrittr_2.0.4 bslib_0.9.0 tools_4.5.2 pkgdown_2.2.0
#> [33] cachem_1.1.0 desc_1.4.3